2020-team11-C04
从 Trac 迁移的文章
这是从旧校内 Wiki 迁移的文章,可能存在一些样式问题,您可以向 memset0 反馈。
原文章内容如下:
[/wiki/2020-team11 返回]
== 概述 ==
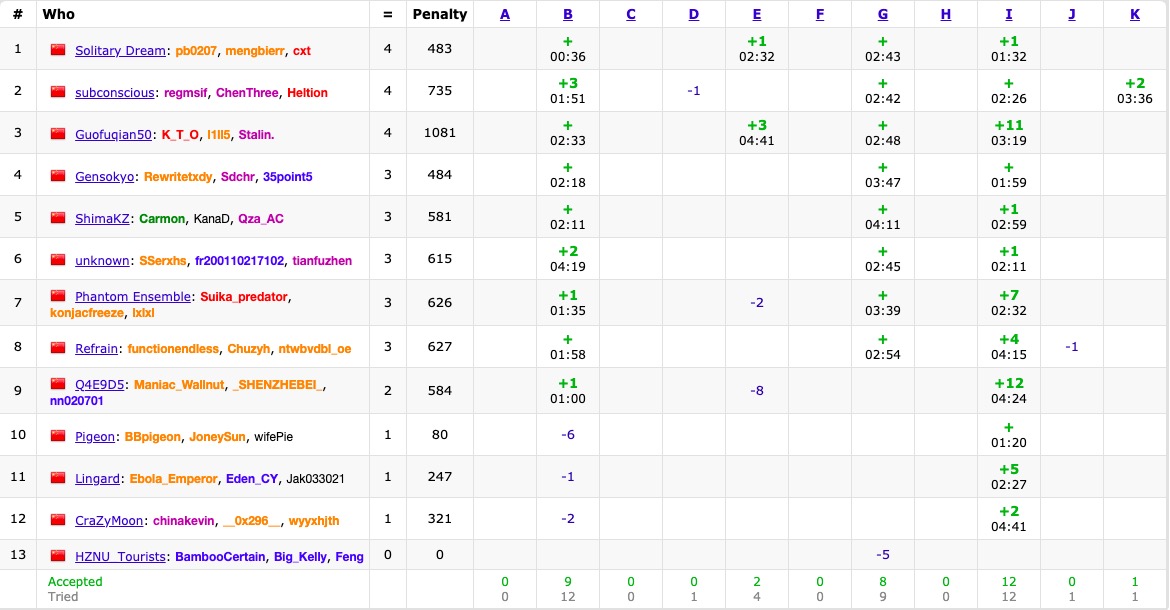
solved: 3/11 dirt: 27%
rank: 5
[[Image(2020-C04.png,700px)]]
== ==
== 总结 ==
Qza 开场倒着看了 K、J、I,发现 J 和 K 都没有什么思路,只有 I 看起来是个标标准准地交互题,于是就在一边等着跟榜一边想 I 的构造。大概想了半小时,Qza 得到了 I 的输出为 O((log,,2,,n)^2^) 的做法,苦思冥想之后没有进一步优化的思路,遂自闭。Qza 读了其他几道题的题面并乱七八糟地想了一会儿后,Zhw说他会 B 了。当 Zhw 写完 B 在调试的时候,Qza 灵光乍现想出了 I 的大概做法,过了一会儿 Qza 抢到了机时,便开始写 I。I 撸了大半时,Zhw 上机把 B 改好并过掉了,全队精神得到了振奋。于是 Qza 继续把 I 写好、过了样例并且 WA5,手造了一组数据把自己卡掉后,Qza 发现自己需要把每棵子树是什么时候被删除记录一下,避免在之后的计算中被重复减掉。然后 I 就过了。
然后 Qza 独自看了一会儿 G,突然发现好像只有连续相同的一段字符才会导致计数出现重复,然后整道题就看起来可做了许多。在 Qza 之前写 I 的时候,Zhw 和 Wjh 一直在讨论 G。Qza 想出 G 的大概思路后,和 Zhw 合计了一下,发现两人思路不谋而合。于是 Qza 开始写 G。写完后,四个样例过了三个,被 300iq 那组样例卡了。仔细思考、讨论后,发现一些之前没有想到过的重复计数(就是该串的所有前缀后缀本身的计数),暴力 for 过去就解决了这个问题。
Qza 觉得今天由于交挂而导致的罚时不多,表现还好(本来就没交什么题)。
== 题解 ==
A:
B: 容易发现在这个数组的子集中,如果出现不满足的情况,那么这不满足的对数中一定有一对是相邻的,即出现最小的异或值一定是相邻的情况.所以只需要先排序,然后按照排序后的顺序扫一遍,将所有数字放到trie树上更新,那么只需要用trie维护以第i个数字结尾的情况数即可.
C:
D:
E:
F:
{{{
#!html
G:先不考虑路径的重复,则总路径有 <img src="http://latex.codecogs.com/gif.latex?2^n-1" /> 条。然后考虑路径的重复问题。发现,当且仅当一个子串中的字符全部相同时,它继续往下走的路径会产生重复。故从答案中减去这部分贡献,再加上真正的贡献即可。假设一段长度为 L 的子串是由原串前面删除 x 个字符、后面删除 y 个字符而获得的,那么从原串获得它的不同方式有 <img src="http://latex.codecogs.com/gif.latex?C_{x+y}^{x}" /> 种,而它本身产生的虚假的贡献为 <img src="http://latex.codecogs.com/gif.latex?2^L-1" />,真实的贡献为 L。然后这种思路被 300iq 那个样例卡了。进一步考虑,发现对于长度为 L 这样的子串,其内长度为 2,3,...,L-1 且与原子串有公共头(第一个字符)或公共尾(最后一个字符)的子子串的贡献还没有被计算,故单独将他们拎出来计算一遍即可,这样复杂度仍然是均摊 O(n) 的。
}}}
H:
I:交互题。先考虑树形为一条链的情况,显然我们可以以最中间那个点为 x,x 左边或者右边相邻的点为 v,,1,,(k=1),这样询问一次,即可根据反馈判断出特殊点 u 是在 x 左边还是右边。于是我们可以在 log,,2,,n 次询问后得到特殊点的位置。将这种思路推而广之,我们钦定一个点为根,每次询问时,以根为 x,以与 x 相邻的若干个点为 v,,1,,, v,,2,,,...,v,,k,,,这样询问一次即可判断出特殊点是否在选定的这些 v 所在的子树内。于是这样进行 log,,2,,n 次询问即可判断出特殊点所在的子树,然后在子树内以同样的方式询问下去。为了保证定位到子树后能大幅度缩小问题规模,我们选取树的重心作为根。但是即便是这样,我们依然需要 O((log,,2,,n)^2^) 次询问才能找到特殊点。产生这个问题的原因在于,我们每次找特殊点所在子树时,仅考虑了子树的数量,在所有子树上二分,而没有考虑到子树的大小。所以应该一次性询问总大小尽可能接近 n/2 的子树,这样能保证问题规模在一次询问后会减少一半。
J:
K:[/wiki/2020-team11 返回]
概述
solved: 3/11 dirt: 27%
rank: 5
总结
Qza 开场倒着看了 K、J、I,发现 J 和 K 都没有什么思路,只有 I 看起来是个标标准准地交互题,于是就在一边等着跟榜一边想 I 的构造。大概想了半小时,Qza 得到了 I 的输出为 O((log2n)2) 的做法,苦思冥想之后没有进一步优化的思路,遂自闭。Qza 读了其他几道题的题面并乱七八糟地想了一会儿后,Zhw说他会 B 了。当 Zhw 写完 B 在调试的时候,Qza 灵光乍现想出了 I 的大概做法,过了一会儿 Qza 抢到了机时,便开始写 I。I 撸了大半时,Zhw 上机把 B 改好并过掉了,全队精神得到了振奋。于是 Qza 继续把 I 写好、过了样例并且 WA5,手造了一组数据把自己卡掉后,Qza 发现自己需要把每棵子树是什么时候被删除记录一下,避免在之后的计算中被重复减掉。然后 I 就过了。
然后 Qza 独自看了一会儿 G,突然发现好像只有连续相同的一段字符才会导致计数出现重复,然后整道题就看起来可做了许多。在 Qza 之前写 I 的时候,Zhw 和 Wjh 一直在讨论 G。Qza 想出 G 的大概思路后,和 Zhw 合计了一下,发现两人思路不谋而合。于是 Qza 开始写 G。写完后,四个样例过了三个,被 300iq 那组样例卡了。仔细思考、讨论后,发现一些之前没有想到过的重复计数(就是该串的所有前缀后缀本身的计数),暴力 for 过去就解决了这个问题。
Qza 觉得今天由于交挂而导致的罚时不多,表现还好(本来就没交什么题)。
题解
A:
B: 容易发现在这个数组的子集中,如果出现不满足的情况,那么这不满足的对数中一定有一对是相邻的,即出现最小的异或值一定是相邻的情况.所以只需要先排序,然后按照排序后的顺序扫一遍,将所有数字放到trie树上更新,那么只需要用trie维护以第i个数字结尾的情况数即可.
C:
D:
E:
F:
G:先不考虑路径的重复,则总路径有H:
I:交互题。先考虑树形为一条链的情况,显然我们可以以最中间那个点为 x,x 左边或者右边相邻的点为 v1(k=1),这样询问一次,即可根据反馈判断出特殊点 u 是在 x 左边还是右边。于是我们可以在 log2n 次询问后得到特殊点的位置。将这种思路推而广之,我们钦定一个点为根,每次询问时,以根为 x,以与 x 相邻的若干个点为 v1, v2,...,vk,这样询问一次即可判断出特殊点是否在选定的这些 v 所在的子树内。于是这样进行 log2n 次询问即可判断出特殊点所在的子树,然后在子树内以同样的方式询问下去。为了保证定位到子树后能大幅度缩小问题规模,我们选取树的重心作为根。但是即便是这样,我们依然需要 O((log2n)2) 次询问才能找到特殊点。产生这个问题的原因在于,我们每次找特殊点所在子树时,仅考虑了子树的数量,在所有子树上二分,而没有考虑到子树的大小。所以应该一次性询问总大小尽可能接近 n/2 的子树,这样能保证问题规模在一次询问后会减少一半。
J:
K:
附加文件
- 2020-C04.png by QwQza