2018-team9-E04
从 Trac 迁移的文章
这是从旧校内 Wiki 迁移的文章,可能存在一些样式问题,您可以向 memset0 反馈。
原文章内容如下:
[[Image(d4.png,600px)]]
[/wiki/2018-team9 返回Sample_Text]
== Contest Information ==
[http://opentrain.snarknews.info/~ejudge/team.cgi?contest_id=001413]
== 流水账 ==
同时开了B & I两道签到题,jt实现B题代码,未发现比赛文件读写要求
wcy实现I题代码,本地与oj编译器区别,ce*1,未清题目输出要求,wa*1,通过
jt添加B题文件读写,pe*4,通过
jt发现J题规律,实现暴力代码,通过
讨论得到K题做法,wcy实现代码,二分的边界出现错误,wa*2,通过
jt得到L题算法,实现代码,本地与oj编译器区别,re*1,过多使用memset被卡成,tle*1,通过
qjc在之前得到H题做法,交由wcy实现代码,未考虑数据范围,wa*1,通过
讨论得到D题做法,wcy实现代码,发现运行时间较长,将所有可能输出打表提交,通过
== 总结 ==
=== jt ===
未仔细阅读题面要求和编译器版本,出现较高罚时,甚至怀疑卡题,浪费了很多时间
最后通过跟榜,以及合理地打表,做出了较少人通过的D题,血赚
在题面阅读、求解和实现的交接上出现了很多题意的偏差和细节的遗漏需要注意
=== qjc ===
签到题出现PE之后没有冷静分析导致连吃4发罚时,和jt学长一起差错的时候漏掉了ll,不够细致。
wcy学长二分题进展缓慢的时候应该早点去帮忙而不是盲目的看题,开的题和做的题应该相对的平衡,而不是把题都开了做不出来
打表赛高
=== wcy ===
1. I题没有注意输出要求,编译时最好应该加上-Wall避免本地与OJ编译器区别引起CE
2. 数据范围应该是做题前后需要注意、检查的重点,因为int和ll的不同导致的罚时已经足够敲响警钟
3. 边界情况还是应该想的时候更清醒、写的时候还原度更高。可以加一些注释,区分不同情况的不同条件
4. 写大模拟的调试能力还应该加强,两个人一起调大模拟虽然最后可做题不多但效率上有点浪费。
== 补题 ==
* A :
* C :
* E :
* F :
* G : 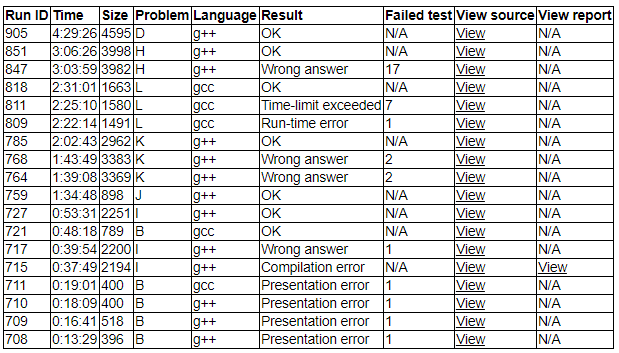
[/wiki/2018-team9 返回Sample_Text]
Contest Information
http://opentrain.snarknews.info/~ejudge/team.cgi?contest_id=001413
流水账
同时开了B & I两道签到题,jt实现B题代码,未发现比赛文件读写要求
wcy实现I题代码,本地与oj编译器区别,ce*1,未清题目输出要求,wa*1,通过
jt添加B题文件读写,pe*4,通过
jt发现J题规律,实现暴力代码,通过
讨论得到K题做法,wcy实现代码,二分的边界出现错误,wa*2,通过
jt得到L题算法,实现代码,本地与oj编译器区别,re*1,过多使用memset被卡成,tle*1,通过
qjc在之前得到H题做法,交由wcy实现代码,未考虑数据范围,wa*1,通过
讨论得到D题做法,wcy实现代码,发现运行时间较长,将所有可能输出打表提交,通过
总结
jt
未仔细阅读题面要求和编译器版本,出现较高罚时,甚至怀疑卡题,浪费了很多时间
最后通过跟榜,以及合理地打表,做出了较少人通过的D题,血赚
在题面阅读、求解和实现的交接上出现了很多题意的偏差和细节的遗漏需要注意
qjc
签到题出现PE之后没有冷静分析导致连吃4发罚时,和jt学长一起差错的时候漏掉了ll,不够细致。
wcy学长二分题进展缓慢的时候应该早点去帮忙而不是盲目的看题,开的题和做的题应该相对的平衡,而不是把题都开了做不出来
打表赛高
wcy
1. I题没有注意输出要求,编译时最好应该加上-Wall避免本地与OJ编译器区别引起CE
2. 数据范围应该是做题前后需要注意、检查的重点,因为int和ll的不同导致的罚时已经足够敲响警钟
3. 边界情况还是应该想的时候更清醒、写的时候还原度更高。可以加一些注释,区分不同情况的不同条件
4. 写大模拟的调试能力还应该加强,两个人一起调大模拟虽然最后可做题不多但效率上有点浪费。
补题
- A :
- C :
- E :
- F :
- G :
附加文件
- d4.png by 233